EU Food Regulation Intelligence
The Problem
If you're a food company launching a product into the EU, you face dozens of overlapping regulations across 17 regulatory categories. Compliance consultants charge €300-500 an hour to navigate EUR-Lex and tell you which articles apply to your product. Most of what they're doing is structured lookup: given a product type, its ingredients, any health claims, and its packaging, which regulations are relevant and what do they require?
I wanted to see how far you could automate that with a RAG pipeline. The system parses 243 EU regulations from EUR-Lex, extracts defined terms and cross-references, routes products to applicable laws deterministically (no LLM involved), then uses semantic search and LLM extraction to produce article-level compliance checklists.
Try it: The live Streamlit app lets you select a product type, ingredients, and claims, then generates a compliance checklist with links back to EUR-Lex for each cited article.
Pipeline Architecture
The pipeline has five stages. The first three are deterministic and run without any LLM calls, which is deliberate: the routing layer guarantees the LLM can only see regulations that were already selected by structured matching. It can't hallucinate a regulation that wasn't routed.
1. Corpus Ingestion
EUR-Lex documents come in at least three different HTML formats spanning two decades of web standards. The parser handles all three (XHTML, old HTML, and a mid-2000s variant) and extracts 2,823 articles across 243 regulations. Along the way it builds an entity index: 702 defined terms (e.g. "novel food means...", "traceability shall mean...") and 1,032 cross-references between regulations.
The corpus is heavily skewed. Official controls alone account for 1,909 of the 5,152 chunks, while food supplements has just 22. This matters for retrieval: a broad semantic search over the whole corpus would drown in official controls articles. The routing layer exists partly to solve this problem.
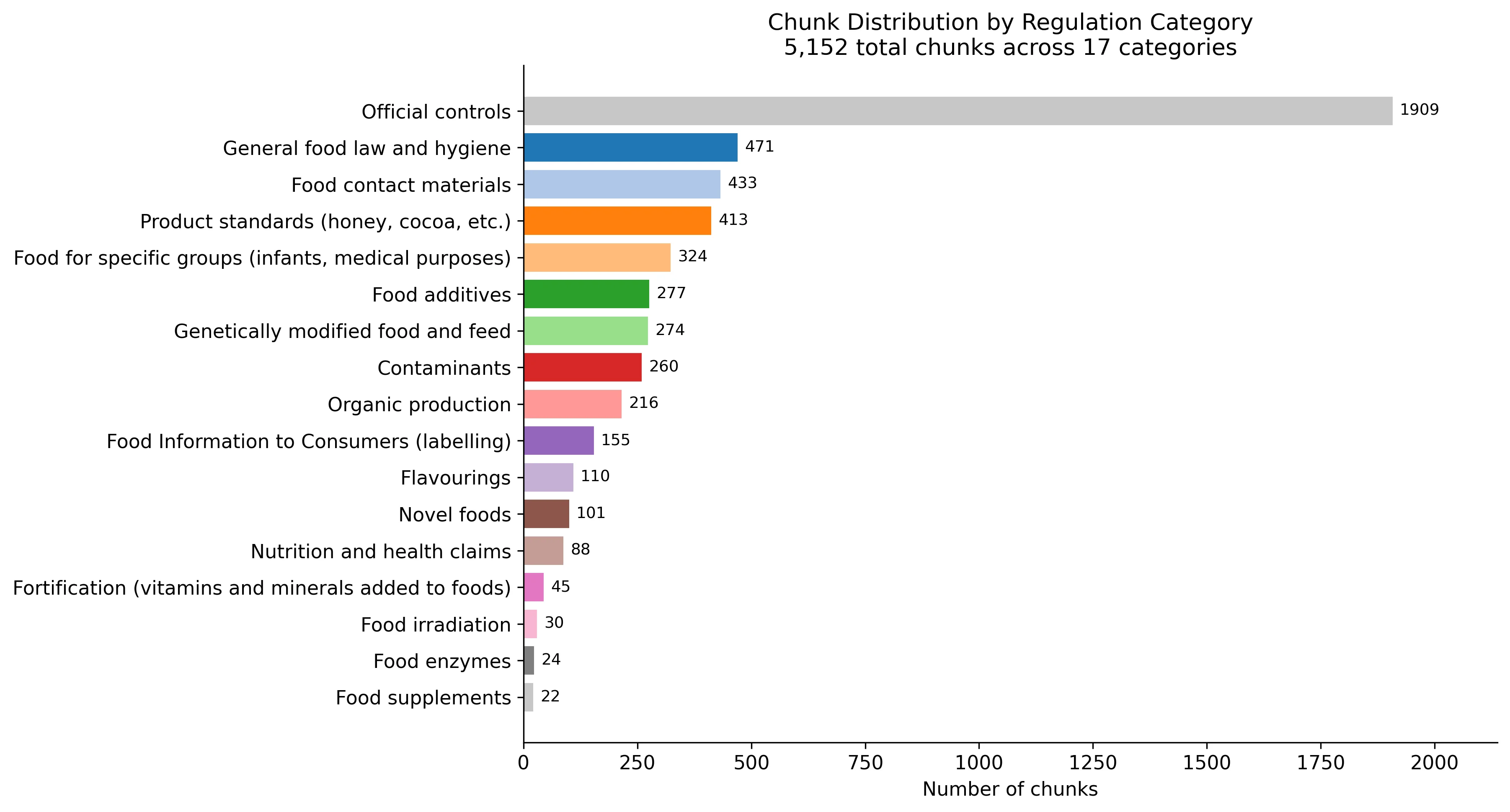
2. Deterministic Routing
Given structured product parameters (product type, ingredients, claims, packaging, keywords), the router maps them to applicable CELEX numbers. It draws on two sources: a manual category routing table encoding domain knowledge, and the entity index for term-level matching. The General Food Law and FIC labelling regulation are always included since they apply to everything.
CATEGORY_ROUTING = {
"novel food": ["novel_food"],
"food supplement": ["food_supplements"],
"health claim": ["nutrition_health_claims"],
"food additive": ["food_additives"],
"allergen": ["labelling_fic"],
"plastic packaging": ["food_contact_materials"],
"contaminant": ["contaminants"],
...
}This is the key design decision. A lot of RAG systems use the LLM to decide what's relevant, but for regulatory compliance you really don't want that. Missed regulations are false negatives with real consequences, and the routing logic is structured enough that a lookup table with entity matching handles it well.
3. Cross-Reference Expansion
EU regulations reference each other constantly. After initial routing, the system does a 1-hop expansion: if Regulation A was routed and cites Regulation B, B gets added to the search pool with lower retrieval priority. This catches tangential requirements that the routing table wouldn't hit directly. It's a trade-off though, and it's the main source of false positives in the evaluation (more on that below).
The network below shows 136 regulations and 328 directed cross-references. The General Food Law sits at the centre (nearly everything references it), with Food Additives, Food Hygiene, and Novel Foods forming dense hubs. The structure explains why 1-hop expansion is both useful and noisy: a single hop from the General Food Law could pull in half the corpus.
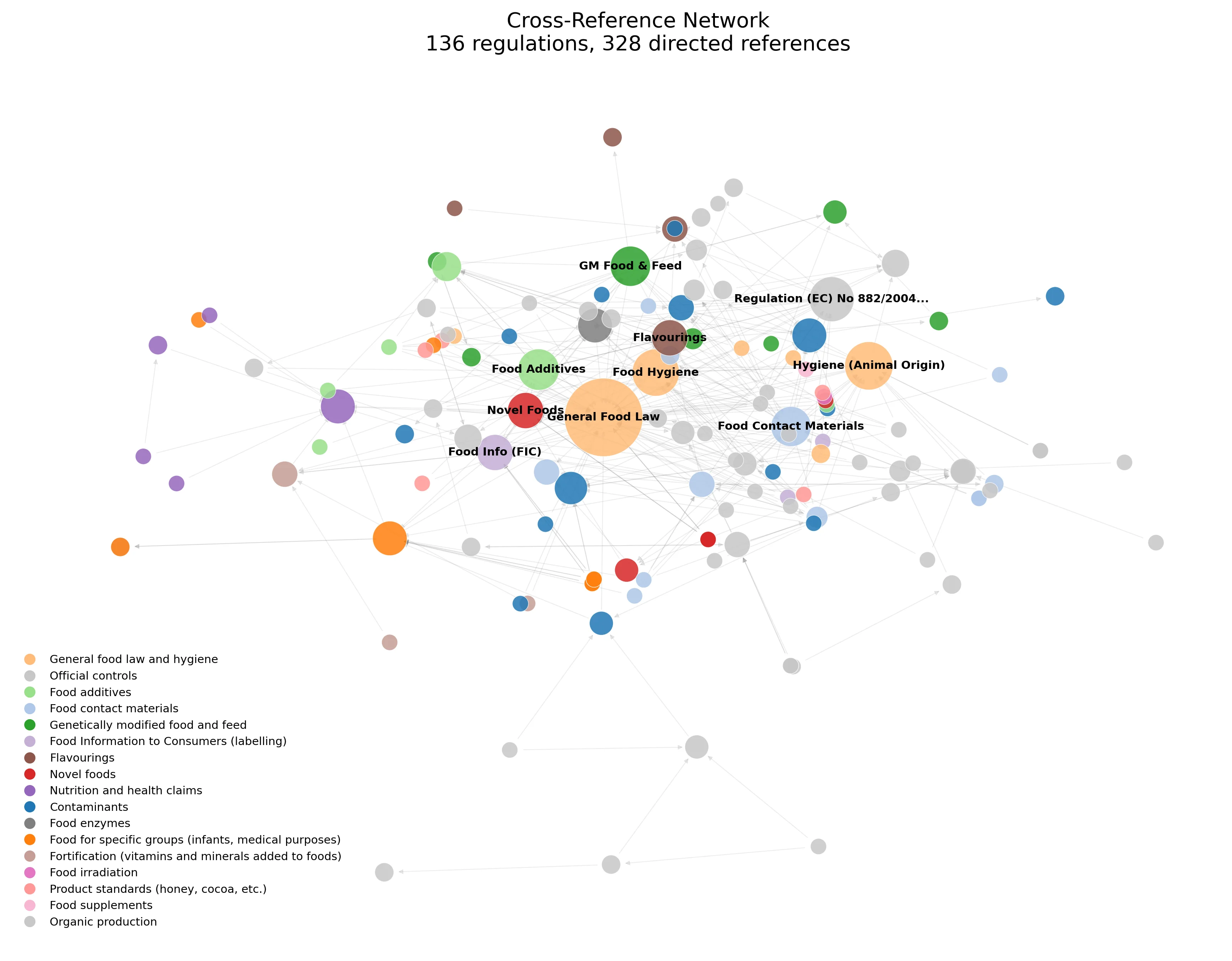
4. Semantic Retrieval
The retrieval stage uses all-MiniLM-L6-v2 via ONNX Runtime (no PyTorch dependency, just NumPy and a 15 MB model). Articles are chunked at the article level with paragraph sub-chunking, giving about 5,152 chunks. Search is hybrid: a broad query across all routed regulations, plus targeted per-regulation queries with tiered allocation (3+ results for core regulations, 1 for cross-refs).
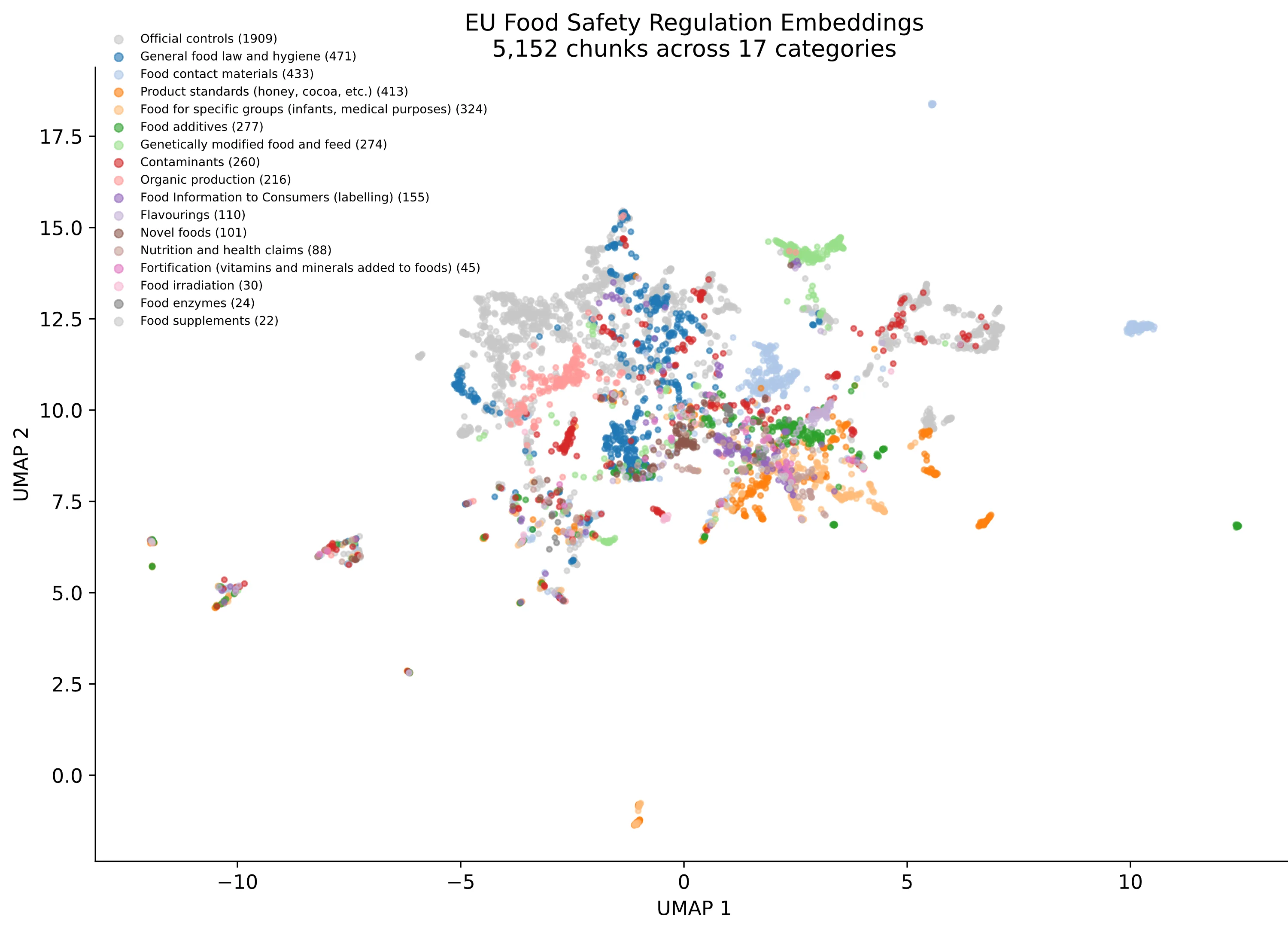
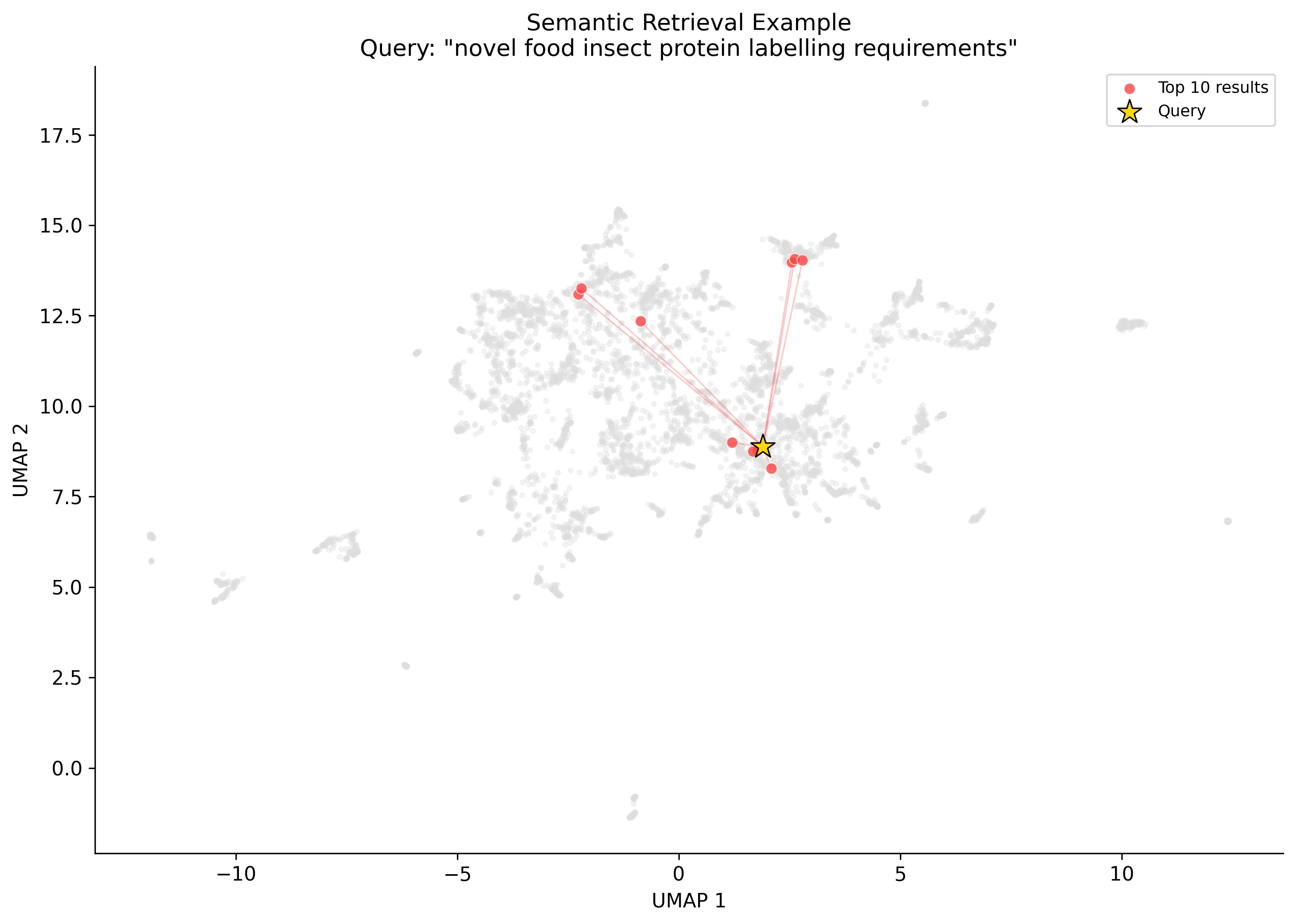
The UMAP projection below gives a sense of the embedding space. Regulations cluster by category, which is what you'd hope for: food contact materials (orange) sit apart from novel foods (pink), and official controls (grey, the largest blob) separate cleanly from the rest. The second scatter shows a retrieval example for "novel food insect protein labelling requirements". The top 10 results (red) pull from several clusters, reflecting the cross-cutting nature of the query.
5. LLM Extraction
The retrieved articles go to an LLM (Anthropic, OpenAI, or a local Claude Code CLI call) with structured output via tool use / function calling. The LLM extracts ComplianceRequirement objects: regulation ID, article number, requirement summary, type (labelling, composition, safety, etc.), priority, confidence, and a source text snippet. Because it only sees pre-routed articles, it can't fabricate citations.
class ComplianceRequirement(BaseModel):
regulation_id: str # e.g. "32015R2283"
article_number: str # e.g. "Article 6(2)"
requirement_summary: str # plain-language description
requirement_type: str # labelling | composition | safety | procedural | ...
priority: str # mandatory | recommended | conditional
confidence: float # 0.0 - 1.0
applicable_to: list[str] # which product aspects trigger this
conditions: str # when this requirement applies
cross_references: list[str] # related regulations/articles
source_text_snippet: str # verbatim from the regulationEvaluation
I built three evaluation scenarios with hand-curated ground truth: an insect protein bar (novel food, 18 requirements), a vitamin D supplement (food supplement, 17 requirements), and an allergen labelling case (17 requirements). 52 ground-truth requirements total, each annotated with regulation, article, type, and priority.
| Metric | Value |
|---|---|
| Precision | 0.58 |
| Recall | 0.69 |
| F1 | 0.63 |
| Hallucination rate | 0% |
The zero hallucination rate is the number I care about most. In a compliance context, a fabricated citation is worse than a missed one: a user can always check what else might apply, but acting on a requirement that doesn't exist in the regulation is actively dangerous.
Failure Analysis
The more interesting part of the evaluation is the failure analysis. Every false negative and false positive gets classified by root cause:
- 100% of false negatives are retrieval failures. The relevant articles existed in routed regulations but ranked outside the search window. The LLM never failed to extract a requirement from an article it actually saw.
- 56% of false positives come from cross-reference expansion. The 1-hop expansion adds tangential regulations that are technically relevant but not core to the query. Valid but noisy.
This tells you exactly where to invest next: a re-ranking layer (cross-encoder or LLM-based) between retrieval and extraction would address both problems. Push relevant articles higher in the search results to fix recall, and demote tangential cross-references to fix precision. The extraction layer itself is working well.
Deployment
The system ships with three interfaces. The Streamlit app has a form where you select product type, ingredients, claims, and packaging from dropdowns extracted from the corpus, then generates a compliance checklist with tabs for requirements, retrieved articles, and routing detail. Each cited regulation links back to EUR-Lex.
There's also a FastAPI REST API with three endpoints (/health, /entities, /compliance-check), and a CLI for local use. The whole thing runs in Docker with no PyTorch dependency, just ONNX Runtime and NumPy for the embeddings.
python -m src.pipeline build # parse EUR-Lex, build indexes (~30s)
python -m src.pipeline query # CLI query
streamlit run app.py # Streamlit dashboard
uvicorn src.api:app # REST API314 tests cover corpus loading, HTML parsing, chunking, routing, vector search, extraction, evaluation matching, and failure analysis.
Summary
- 243 EU regulations parsed (2,823 articles, 702 defined terms, 1,032 cross-references)
- Deterministic routing layer — no LLM decides which regulations apply
- Semantic retrieval via ONNX embeddings (all-MiniLM-L6-v2, 15 MB, no PyTorch)
- Structured LLM extraction with zero hallucination rate across 52 ground-truth requirements
- Precision 0.58 / Recall 0.69 / F1 0.63 — bottleneck is retrieval, not extraction
- Streamlit UI + FastAPI REST API + CLI, Docker-deployable
- 314 tests passing