Professional Experience
Professional Experience
My Ph.D. focussed on predicting tipping points in dynamical systems using multi-dimensional time series data, which I thought to be a great jumping-off point for a career in Data Science: I'm good with statistics, problem solving, implementing algorithms and working with data.
I work in mainly in Python and SQL, but I have experience with creating and maintaining databases, dashboards and full-stack software projects. I have implemented and used a variety of Machine Learning algorithms.
In a recent role at Blink SEO I built the company's internal software from scratch, increasing productivity by 20× by automating all data processing and generating data-lead recommendations through machine learning. This software improved the SEO process so much that we marketed it as a SaaS app to other agencies: Macalytics. You can find a pdf-format CV here.
Data Consultant & Architect
Architecting scalable pipelines and ML infrastructure to drive business goals
Data Scientist
Building innovative data science solutions for SEO productivity
Data Scientist / Full Stack Developer
Revolutionizing SEO data engineering with innovative software
Researcher Scientist
Ph.D. research industrial collaboration: Tipping points in dynamical systems
Associate Lecturer
Teaching Mathematics and Computer Science at Undergraduate and Masters level
Informatics Developer
Creating a solution for the integration of amateur weather data
Teaching Assistant
Supporting undergraduate mathematics and computing courses during MRes
Trainee Teacher
PGCE in Secondary Mathematics with placements in state and private schools.
Portfolio
Portfolio
A selection of data science and analysis projects. More projects can be found on my projects page.
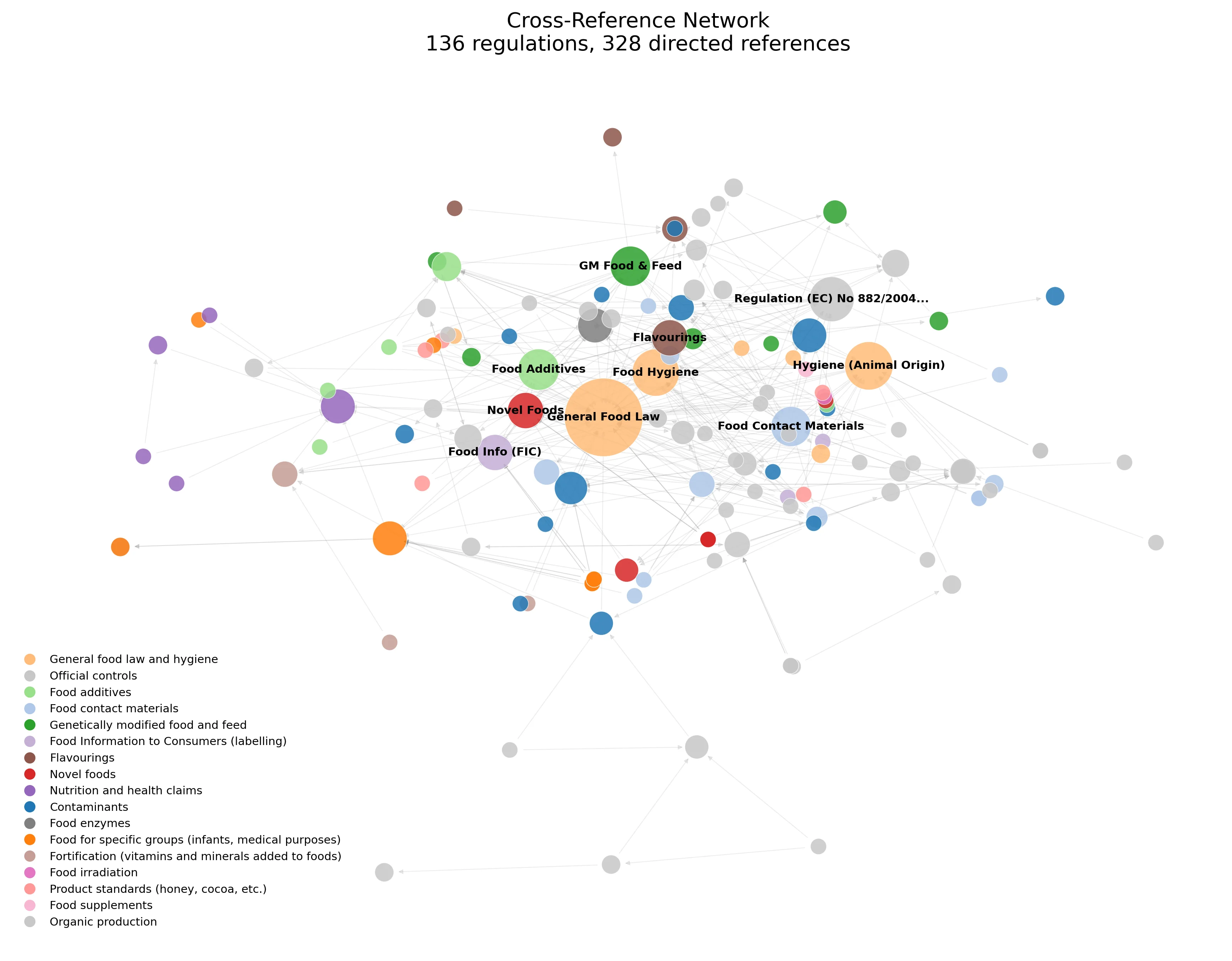
RAG pipeline that parses 243 EU food regulations, routes products to applicable laws deterministically, and extracts compliance checklists with zero hallucinations.

Analyses 2.57M EU food products to identify where retailers can launch health-positioned private label products into underserved nutritional gaps.

Multi-source data pipeline and hybrid recommendation engine that identifies underserved game niches on Steam, scoring 140,000+ market opportunities with revenue estimates.
JobSearch Agent
AI-powered CLI tool that automates job hunting: searches the web for relevant positions, intelligently filters based on your background, and generates tailored cover letters as professional PDFs.
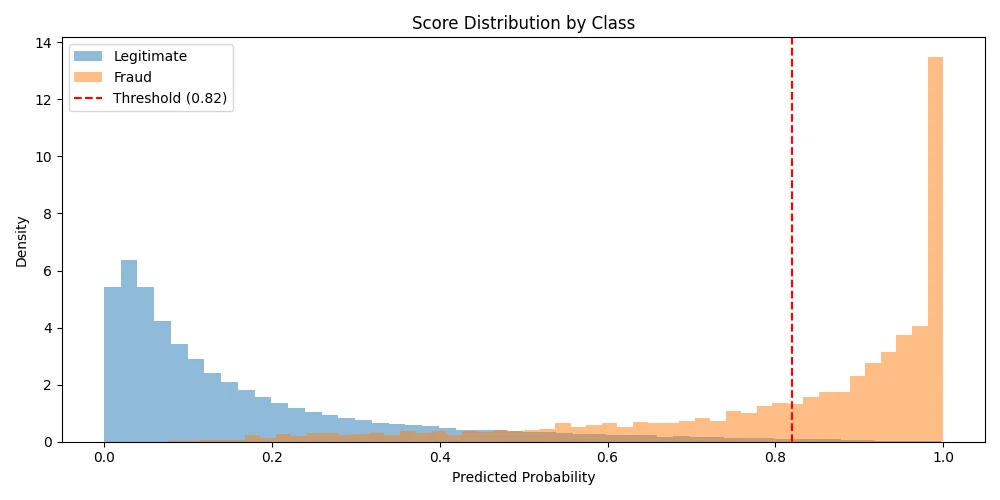
Fraud Detection
Cost-sensitive fraud detection achieving 97.4% AUC and $447K annual savings. Features time-based CV and business-optimized thresholds.

A data viz project to create an interactive world map showing wine imports and exports. Can also map other traded commodities using the UN's Comtrade data.
Technologies and Skills
Technologies and Skills
I work mainly in Python, utilising various packages for data mining, machine learning, visualisation, web-scraping, and most other things. I also have extensive experience working with SQL, JavaScript and a host of other technologies.
I've spent a lot of time working with ScikitLearn, PyTorch and TensorFlow for machine learning tasks, and using NLP for working with textual data.
- NLP using NLTK, and DBSCAN clustering on Search Console data to provide recommendations for primary keywords. This cut down a days-long spreadsheet-scrolling task to a few minutes.
- A combination of classification and clustering to recommend new category pages for D2C brands with a focus on optimising click-through rate and capturing niche keywords whilst reducing cannibalisation.
- LLM intergration (Ollama, Huggingface) to provide highly personalised recomendations for on-page copy. This allowed new pages to be launched in minutes rather than days.
I designed and implemented the Blink SEO data warehouse in BigQuery. This saved the team from the manual csv-export/excel-import repetative nightmare –freeing up countless hours– and provided consistent data for future dashboards, front-end dev, and ML methods.
- Wrote the PyGoogalytics package for data extraction from Google Ads, GA4 and Search Console in a consistent format.
- Plus wrappers for other services such as Shopify (GraphQL) and SemRush (REST).
- Python scripts for cleaning data and loading into BigQuery.
- Dozens of table functions and views to aggregate data across different sources to easily query key business metrics.
I built the Macalytics backend in Python running on a GCP Compute Engine virtual machine. This connected to client data sources via APIs, handled Data Cleaning and ML tasks, integrated with BigQuery and communicated with the front-end.
- Set up Slack notifications from the backend system to alert devs (me) of tech problems and agency staff of clients' statuses.
- Created a job-queue system (PostgreSQL) for running back-end processes on demand and on schedules.
- Created a web-scraping process based on Scrapy.
- Set up Python scripts in Google Cloud Functions with API endpoints to onboard users into the system.
Data is useless if it doesn't tell you anything. I've produced visualisations throughout my accademic career for posters, papers and presentations. More recently I've created interactive dashboards to communicate KPIs, and as playgrounds allowing users to explore data in meaninful ways.
- Visualisations created with Matplotlib and Plotly: from academic papers to investor reports.
- Looker Studio dashboards as prototypes for quick feedback and integration.
- I created the Macalytics frontend in Retool (JavaScript) incorporating multiple dashboards:
- Client-facing dashboards to replace time-consuming monthly PDF reports, saving hours per client per month,
- Agency-facing dashboards for data exploration and the ability to implement business descisions with a click, dramatically increasing productivity.
Notes
Notes
I've seen the same question come up several times during job applications and interviews: "What is important to you in a job?" So I'm going to answer it.
I think I want to take it easy, I look forward to the easier things, but when it actually comes to it I get bored. I need a challenge, or something new to learn, otherwise I'm not at my best.
I'm always asking questions. I don't want to just do the task: I want to know why I'm doing it, who's it helping? What is it trying to achieve? Ask the SMEs for their thoughts, ask the management what the priorities are: let's work together and make something great.
It definitely helps to feel that the work is useful to someone, aside from just making money. If I improve a process or add a feature and it increases revenue, that's great, but even better is the team telling me it saved them time or helped them out.